SANDBOX /
/ 試作・実験
SANDBOX / 試作・実験
2026.06.02.
SANDBOX
知識収集・検証スタジオ
業務文書に対して AI が「それっぽい嘘」を返すのは、データが整っていないから。取り込み段階で文書を意味の単位に整え、現場の問いに出典つきで答える研究・調査スタジオ。
- Next.js 15
- FastAPI
- Neo4j
- Qdrant
- OpenAI / Anthropic
- Brave Search API
「この業務の手順を教えて」「あの案件の経緯はどうだった」── 現場でそう問いを投げたとき、いまの AI は 本来欲しい答えを返さない ことが多い。それらしい手順を作り上げたり、過去の回答と一貫しなかったり、肝心の文書まで辿り着けなかったりする。AI 側の能力の問題ではない。検索対象のデータが、そもそも整理されていない ことが原因である。RAG やデータ分析基盤を入れても同じ壁にぶつかるのは、ここを飛ばして「とりあえず文書を放り込む」設計になっているからだ。
本ツールは、文書を取り込んだ瞬間に本文を意味の最小単位「主張(claim)」に分解し、出典・確度・関係をナレッジグラフ化する。汚いデータを「使える状態」に整える工程をビルトインで持つ ことで、業務の問いに対して出典で裏取れた検証済みの答えを返せるようにした。他社の AI 調査結果を貼り付ければ、同一基準で並べて採点・比較もできる。
そしてもう一つの軸がある。整えた後にも、資料同士の食い違いや現場の人にしか分からない最新の事情は必ず残る。本ツールはそれを AI が勝手に判定せず、前提と見立てを添えて人に問い返す。返ってきた一言は知識ベースに記録され、以後の検索・調査にずっと効いていく。「答える AI」ではなく「引き出す AI」 を、検証の中心に据えている。
集める・整える・調べる・検証する・問い返す ── これが本ツールの 5 つの仕事である。
何を作ったか
情報を「使える状態」に整えるところから始める基盤である。
PDF・社内文書・Google Drive・Web の調査結果を、同じ土俵に乗せる。そして文書をそのまま放り込むのではなく、本文を意味の最小単位「主張(claim)」に分解して整える ── ここが起点である。一つひとつの主張は、抽出元の引用箇所に厳密に紐づき、事実・方針・予測・意見・前提・定義といった種別と、確からしさ(確度)を持つ。
主張はエンティティ ── 企業・人物・指標・制度 ── や、他の主張との関係 ── 支持・矛盾・関連 ── でつながり、文章のままではなくナレッジグラフとして横断できる。これにより、検索・調査・質問の対象が「どの文書か」ではなく「どの主張か」になる。問いを投げれば、調査エンジンはこのグラフと Web を行き来しながら答えを組み立て、回答を作るたびに「各文が出典で裏取れているか」を別の工程で監査する。
ドキュメント単位で曖昧に返すのではなく、意味の単位で、出典つきで、検証された状態の答えを返す。これが本ツールの設計の中心にある。
なぜ作ったか
情報は無数にあるのに、必要な一つを取り出せない。これは多くの組織・個人に共通する課題である。
その解決策として導入される RAG やデータ分析基盤は、しかし、まともに機能していないことが多い。膨大な情報をうまく統合できず、肝心のデータをそもそも正しく取ってこれない。原因は明快で、整っていないデータをそのまま放り込んでいるからである。文書をまるごとベクトル化しても、返ってくるのは「それらしい断片」であって、問いに答える意味の単位ではない。
本ツールは、ここを逆から設計した。まずデータをきれいにする ── 文書を主張という意味の単位に分解し、出典に紐づけ、関係で構造化する。整ったデータの上で初めて、検索・調査・質問は意味のある答えを返す。さらに、返す答えが出典で裏取れているか、論理に飛躍はないかを常に監査し、信頼できる状態で差し出す。AI に判断を委ねきるのではなく、人が最後の判断を下すための材料を、検証可能なかたちで取り出せるようにすることを狙った。
検証を機械に任せきっても、どれが本当に正しく、なぜそう書かれたのか は、その知識を持つ人しか分からないことが多い。だからこのツールは、AI が食い違いを見つけたら 人に問い返す。人が現場の事情や最新の状況を一言添えるだけで、知識ベースはより正確に育っていく。「答える AI」ではなく「引き出す AI」を、検証の中心に据えた。
できること
取り込みと構造化
PDF・社内文書・Google Drive を取り込み、本文を主張単位に分解する。出典引用・エンティティ・主張間の関係(支持・矛盾・関連)をナレッジグラフ化する。営業ノウハウのような経験知は、無理に細切れにせず一つの知見として扱う。
ディープリサーチ
複数ラウンドの自律検索で問いに答える。曖昧な問いには「最も知りたかったであろう狙い」を推定してスコープを明示し、答えを出し切る。各主張に出典を付与し、回答が出典でどこまで裏取れているか(接地性)を監査する。
ファクトチェックと論理レビュー
文書・調査結果の各主張を Web 検索で外部照合し、支持・反証・賛否混在・根拠不足を判定する。あわせて、内部の論理矛盾・飛躍・過度な一般化をレビューする。
食い違いの確認(AI からの確認依頼)
複数の資料のあいだ、あるいは同じ資料の中で内容が食い違っているところを AI が自動で見つけ、人に確認を求める。資料の全文を左右に並べて見比べながら、どちらが正しいか・どちらが最新か・なぜ違うのかを、音声でも手入力でも答えられる。AI はいきなり正誤を問わず、前提を説明し、自分の見立てを根拠つきで添えて提案する。答えた判断は元データとは別に記録され、以後の検索・調査に反映される。
接地性の独立検証
出典で裏取れなかった主張を、引用とは無関係に Web で再検証し、命題そのものの真偽を確かめる。
品質採点と比較
調査結果を、接地性・引用正確性・網羅性・深さ・最新性の 5 軸で採点する。他社ディープリサーチの結果を同一基準で貼り付ければ、横並びで比較できる。採点に使ったデータは保存され、基準を変えても貼り直さず一括で再採点できる。
PlayGround と校正
原文プレビューとナレッジグラフを並べ、クリックで相互に連動させる。関連ノードだけを辿ることもできる。原文の誤り・誤解箇所はマークして検索から除外、あるいは注釈コメントとして残せる。
デモ動画
文書の取り込みから、矛盾の検出、音声による確認、整備後の調査までを一続きで実演している。
目玉機能 ── AI が音声で問い返し、人の判断で元データが整っていく
ファクトチェックや RAG が 「外形的に正しいか」 までしか判定できないのに対して、本ツールの中心にあるのは 「どちらが本当に正しいか・どれが最新か・なぜそう書いたのか」を、知っている人間から音声で引き出す工程 である。AI が資料間や同一資料内の食い違いを自動で検出して確認依頼として一覧化する。1 件ずつ進める「個別確認」のほかに、「まとめて確認」モード では複数件を連続で消化していける。
画面の構造
- 左右に、食い違う 2 つの主張 ── 抽出元の文書とハイライト箇所が同時に出る
- AI の見立て ── なぜ食い違って見えるか、根拠つきで添える。例: 「A は『年間 100 社導入』という流量っぽい表現、B は『導入企業 30 社に拡大』という累積っぽい表現で、同じ指標として読むとずれます」
- 4 段階の構造化された確認パネル
- どちらが正しいか ── A が正しい / B が正しい / 両方とも正しい / どちらも不正確 / 文脈による
- どちらが最新か ── A が最新 / B が最新 / 両方とも現役 / 不明
- 誤っている主張を直す(任意) ── 誤りとして記録する主張を選ぶ。赤枠 = 誤り・古い / 金枠 = 採用 で視覚的に確定する
- 意図・背景メモ(任意) ── なぜ食い違ったか、どちらを採用すべきかの背景。音声で話した内容は自動で書き起こされてここに入る
- 修正案も AI が提案 ── 採用された側に合わせて、元のドキュメントを どう書き直すか までテキストで先回りして提示する。OK と言えば、元文書自体がその案で更新される
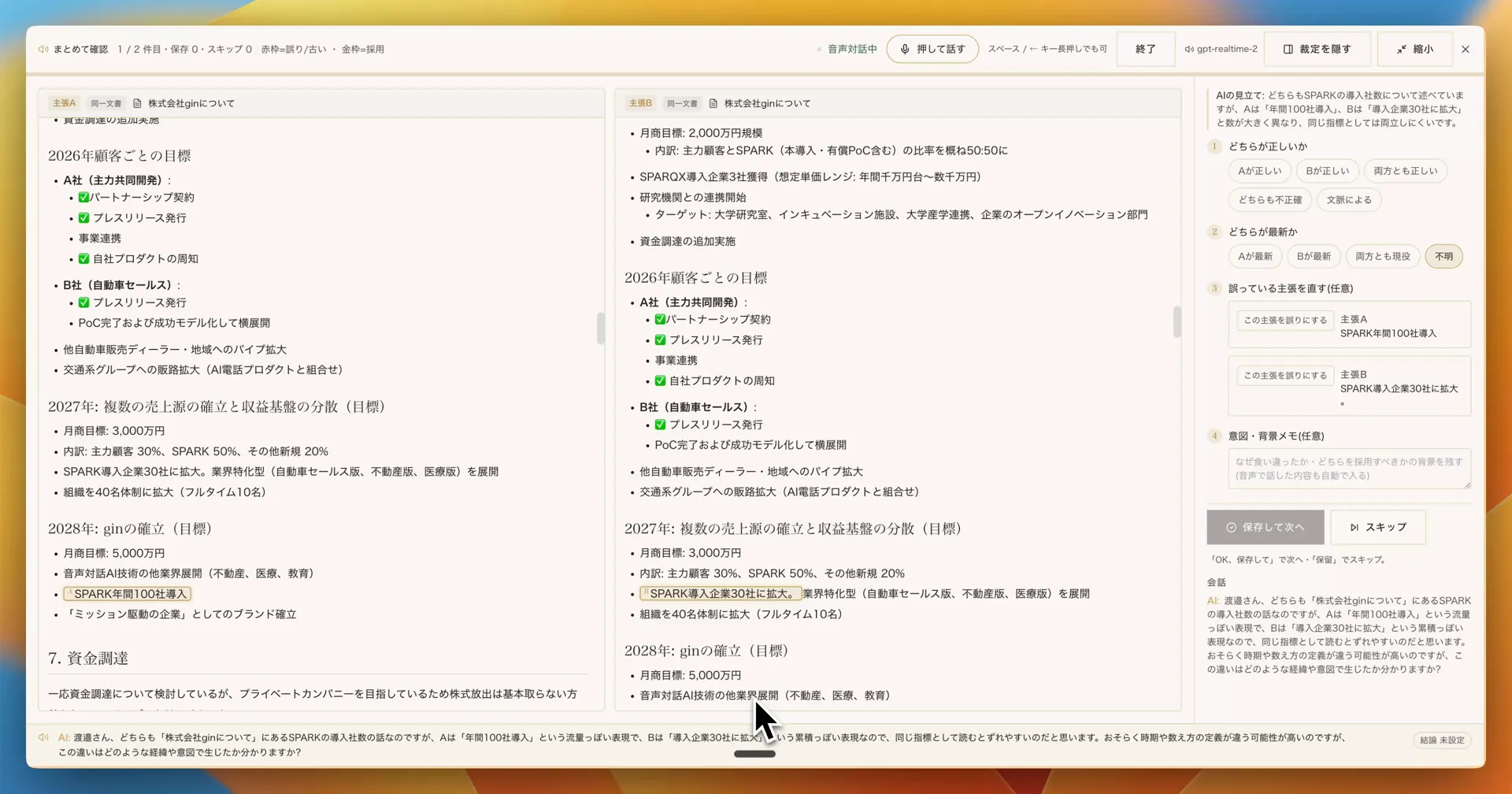
例:A「SPARK 年間 100 社導入」と B「SPARK 導入企業 30 社に拡大」── 数字が大きく異なる SPARK の導入指標について、AI が「流量と累積で読み方が違うのではないか」と整理し、利用者から経緯を引き出す。
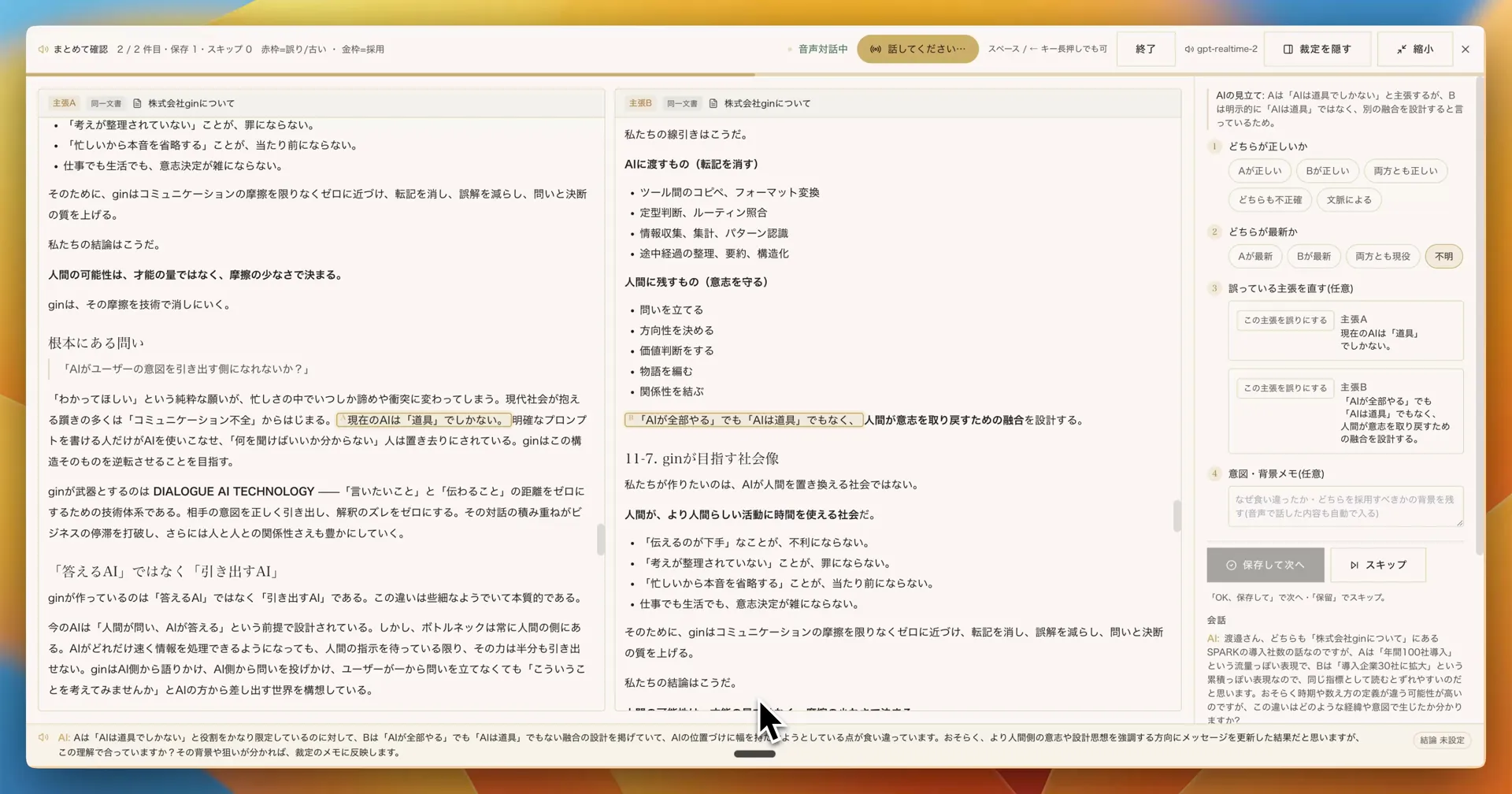
別の例:A「AI は道具でしかない」と B「AI は道具でも全部やるでもなく、人間が意志を取り戻すための融合を設計する」── 立場の更新が起きたとき、AI が前提を整理して「最新メッセージに合わせる方針として採用」を提案する。意図・背景メモには音声で話した内容が自動で書き起こされ、後で裁定の根拠として残る。
音声対話の作り込み
- Push-to-Talk(スペースキー長押し、または「押して話す」ボタン)── 常時聞き取りではなく、押している間だけ送話する安全な設計
- バックエンドは OpenAI Realtime API(gpt-realtime) で、低遅延の対話を実現
- AI はいきなり正誤を聞かない。前提を説明 → 自分の見立てを根拠つきで提案 → 人の一言を待つ ── 押しつけない構えを徹底
- 人が一言答えれば「保存して次へ」で次の食い違いに進み、整理は連続して消化されていく
- 裁定結果は元のドキュメントを書き換えるだけでなく 知識ベース上で誤った主張を格下げ、以後の検索・調査では正しい情報が優先される
画面
主要な 4 つの仕事の入口を 1 画面に集約。取り込みからナレッジグラフ閲覧まで、ここから直接たどれる。
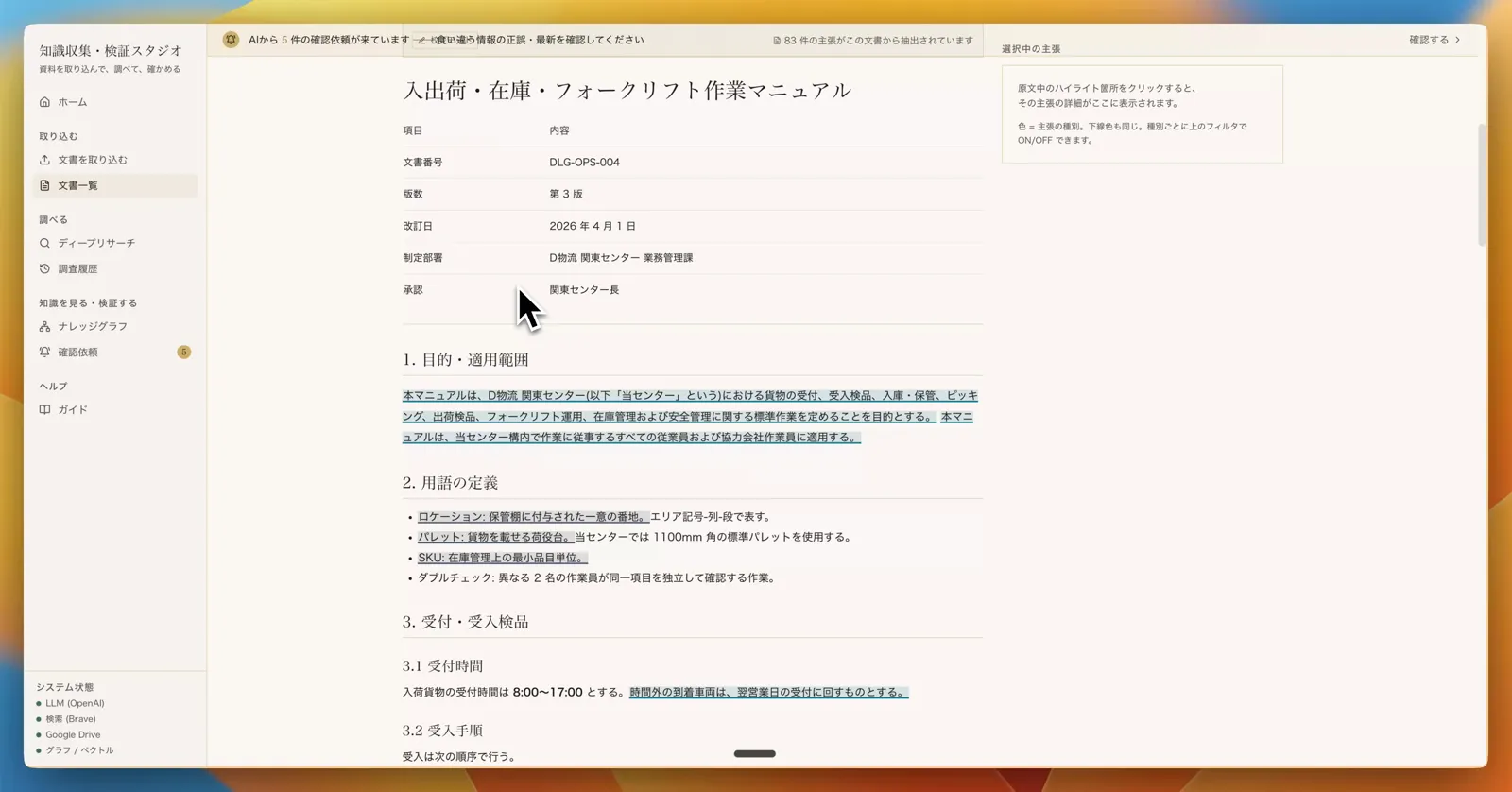
取り込まれた文書は主張(claim)単位に分解され、種別(事実 / 仮説 / 方針 / 条件付き定義 …)と確からしさのラベルが付く。原文と一対一で紐づくので、クリックすれば抽出元の文章に飛べる。
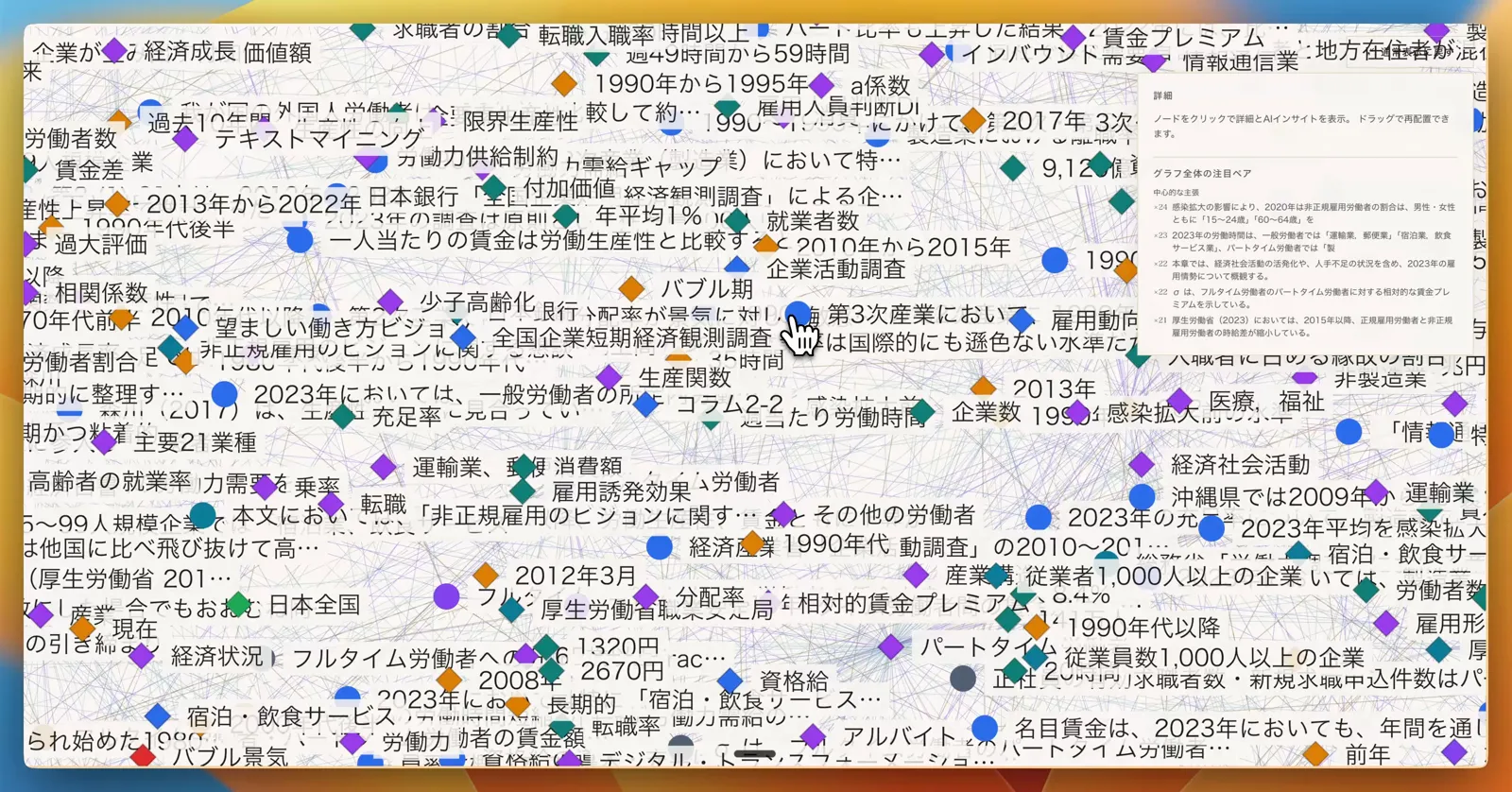
主張・エンティティ・関係をグラフで横断する。文書をまたいで「どこから来た情報か」「何が支持・矛盾しているか」を構造ごと見渡せる。
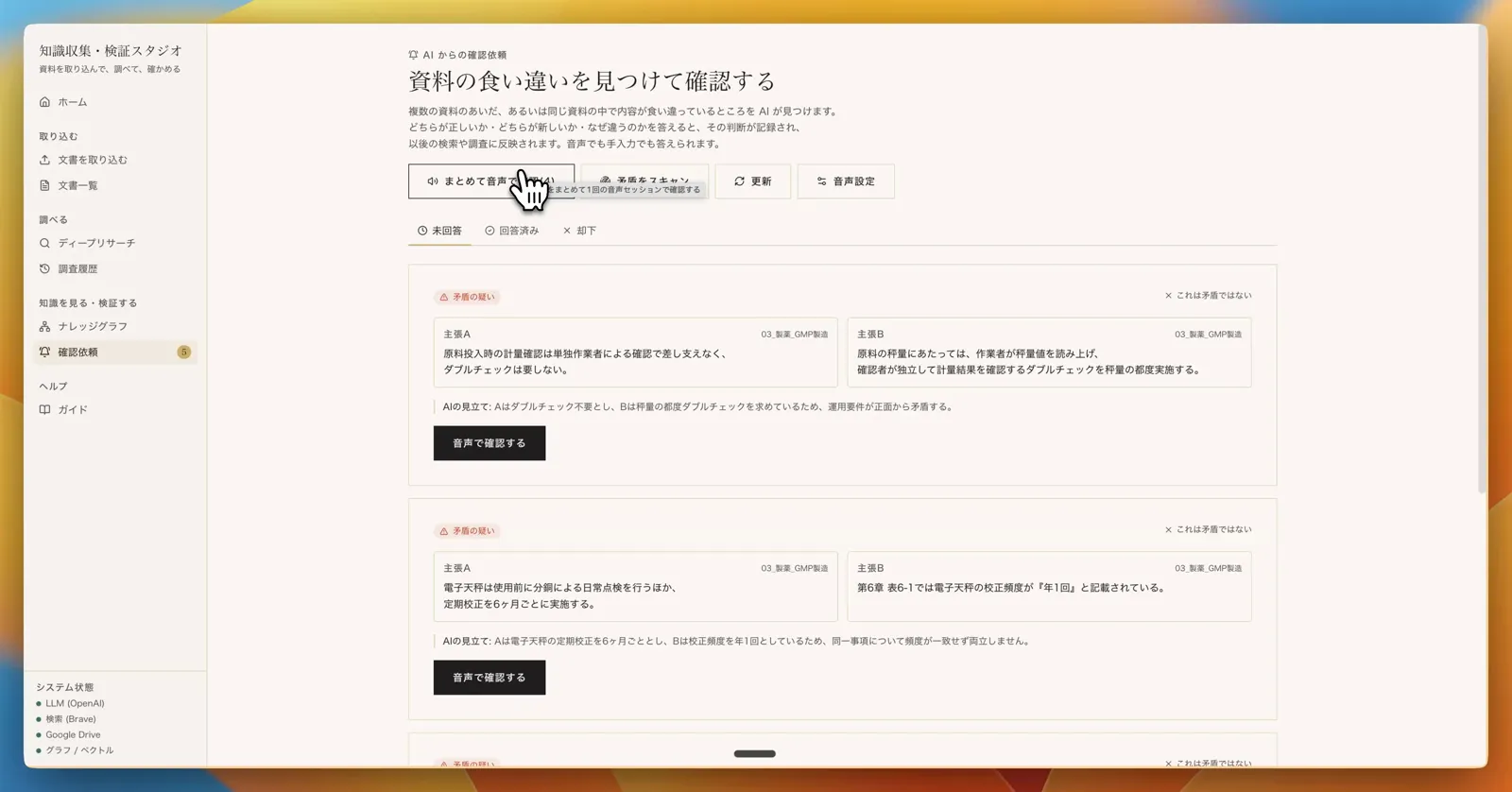
資料間の食い違いを AI が自動スキャンし、確認依頼として一覧化。各カードには「どの資料の何と、どの資料の何が」「なぜぶつかっているのか」が要約されている。
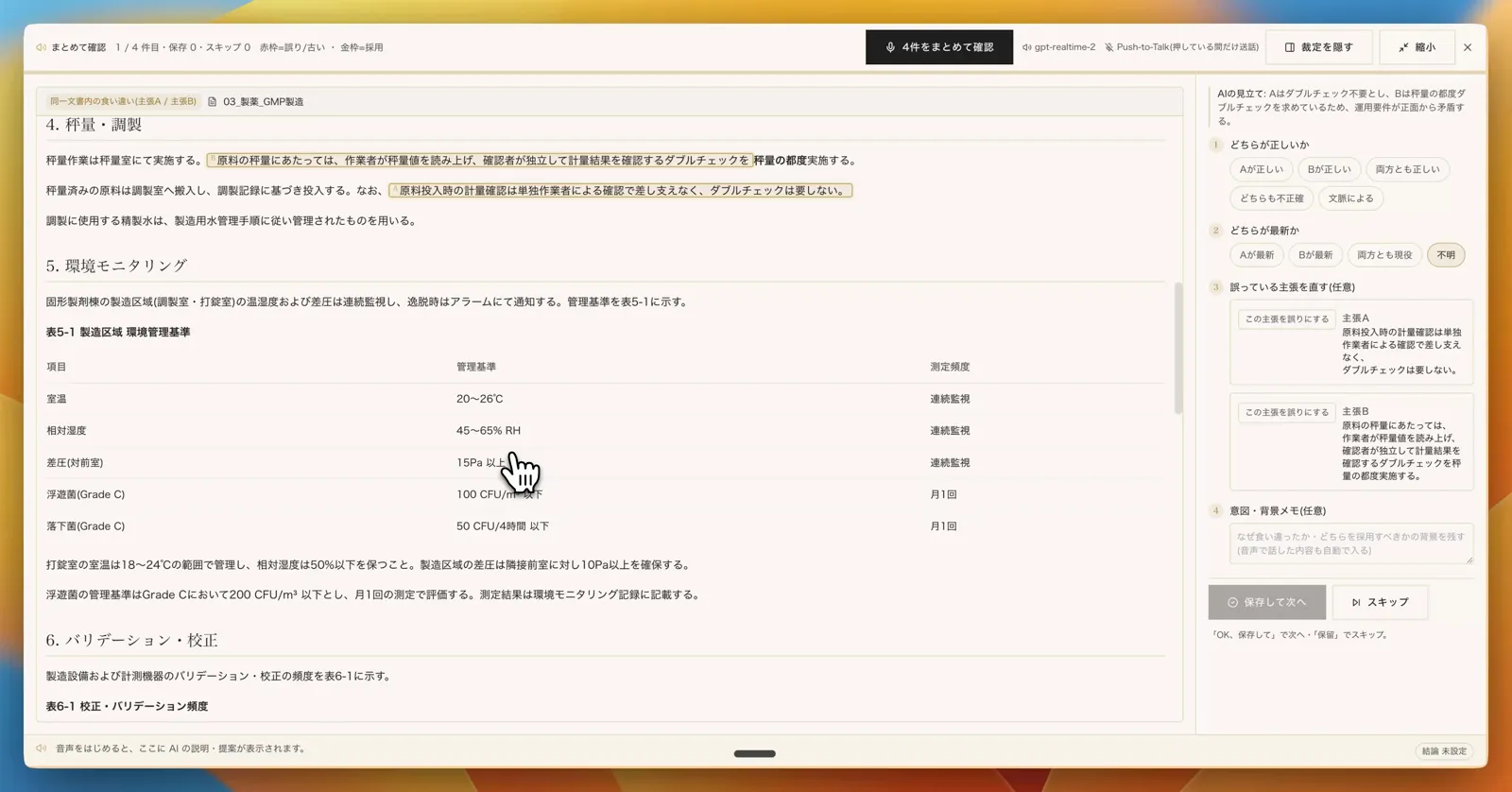
食い違う 2 つの文書を左右に並べてハイライト。AI が前提と見立てを音声で説明したうえで、人に確認を求める。人が一言答えれば、元のドキュメント自体が修正・保存され、知識ベースに反映される。
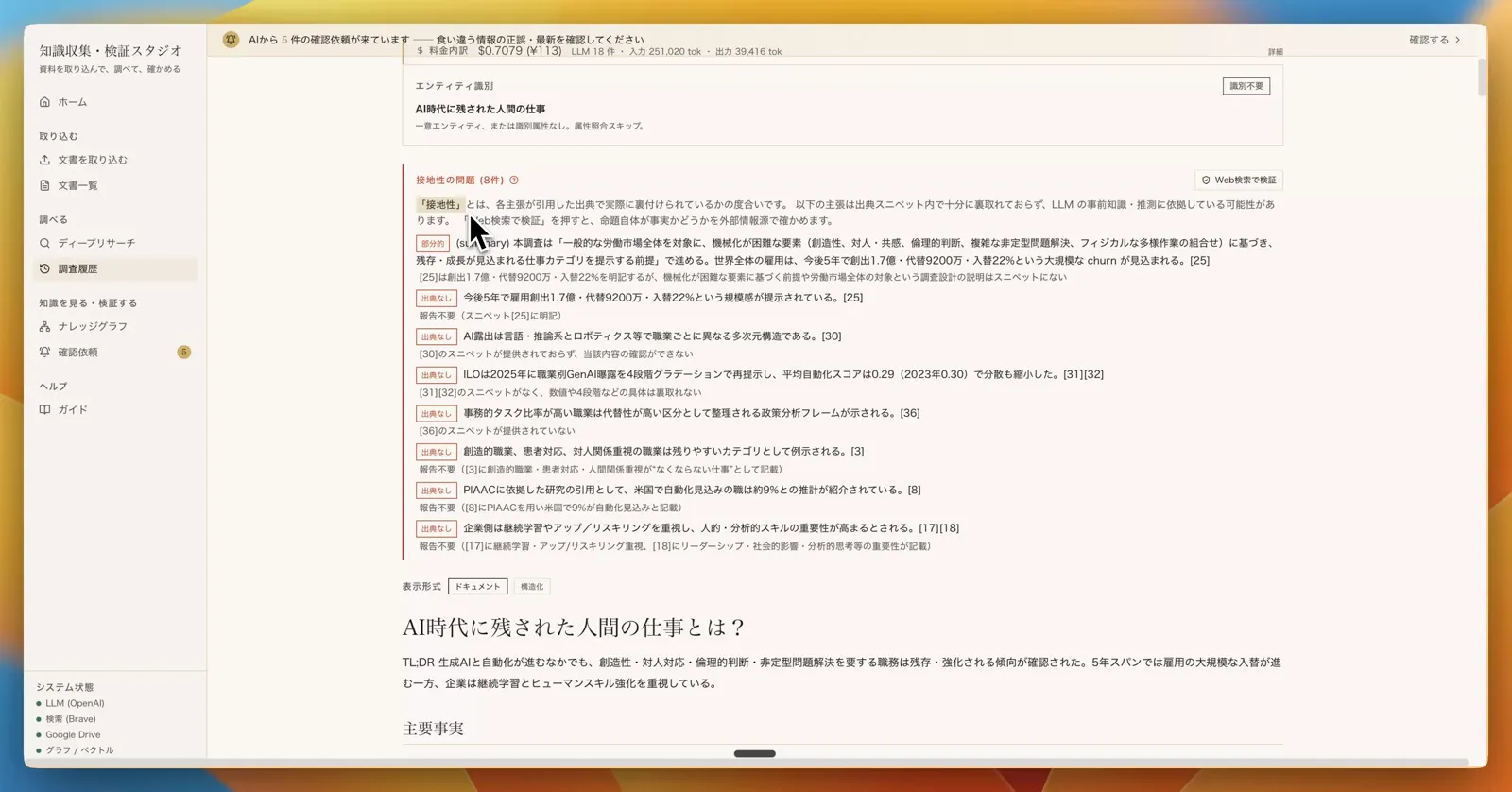
整ったデータと Web を併用して自律調査。回答の各文に出典を紐づけ、どこまでが裏取れていて、どこから AI の推測か を文単位で指摘する。
他のツールと何が違うのか
一般的な RAG は、整っていない文書をそのまま検索対象にする。だから返るのは「それらしい断片」であり、問いに答える意味の単位ではない。本ツールは、文書を主張という意味の単位に整える工程を起点に置く。検索・調査・質問の対象が「どの文書か」ではなく「どの主張か」になり、さらにその答えがどこまで裏取れているかまでを返す。
念のため付け加えると、ベクトル検索やセマンティック類似による意味検索といった、一般的な RAG が中核に置いている技術は本ツールの内部でも当然活用している。RAG が単独でやっていることはひととおりこちらでもカバーしたうえで、その前にデータ整備層を、後ろに検証と人への確認の層を足している ── そういう積み増しの関係で読んでもらうと、位置づけが見えやすい。
| 一般的な要約 / RAG | 本ツール | |
|---|---|---|
| データの扱い | 文書をそのまま投入 | 主張(意味単位)に分解・整理してから扱う |
| 取り出す単位 | 文書 / チャンク | 意味の単位 = 主張。問いに直接答える |
| 出典との関係 | 参考として併記 | 引用箇所に厳密に紐づき、裏取れ度合いを監査 |
| 知識の蓄積 | チャットログ / ベクトル | ナレッジグラフ(主張・エンティティ・関係) |
| 検証 | 利用者が目視 | Web 照合・論理レビュー・5 軸採点を内蔵 |
| 食い違いの扱い | 利用者が気づくまで放置 | AI が検出し、人に確認を求めて知識として記録 |
| 自己評価 | なし | 自分の出力を採点し、他社と同一基準で比較 |
| AI の役割 | 答える | 答えるだけでなく、人に問い、暗黙知を引き出す |
そして本ツールは、自社の調査結果も同じ物差しで採点する。同一の問いで他社の最上位ツールと比較すると、出典の裏取り(接地性・引用)では肩を並べる一方、網羅性や深さでは学ぶべき点が残る ── そうした結果も率直に表示する。隠さず測り、改善の起点にすること自体を、機能として組み込んでいる。
想定する使い方
- 商談・営業準備 ── 取引先企業の資本関係・沿革・直近動向を出典つきで要点化する。社内の営業ノウハウ資料も知見として取り込み、横断して引ける
- リサーチの裏取り ── 既存の調査レポート(自作・外部ツール製を問わず)を取り込み、各主張を Web で再検証して、鵜呑みにできない箇所を洗い出す
- 社内ナレッジの構造化 ── 蓄積された文書を主張グラフ化し、誰がどの根拠でそう言っているのかを辿れるようにする
- AI 出力の品質管理 ── 他社ディープリサーチの結果を同一基準で採点し、用途に足る品質かを定量的に判断する
技術スタックと工夫
フロントエンドは Next.js 15(App Router)、バックエンドは FastAPI。知識はグラフ DB の Neo4j とベクトル DB の Qdrant に保持し、Web 検索は Brave Search を用いる。LLM は OpenAI を主、Anthropic をフォールバックとし、高速モードは合成のみ上位モデルを使うハイブリッド構成とした。全体は docker-compose で統合し、ローカルで完結して動く。
取り込みは、ジャンル分類(事実情報 / 経験知)→ 主張抽出 → ベクトル化 → エンティティ抽出 → 関係エッジ生成 → 論理チェック → 重複の集約、という流れで進む。
実装で特にこだわった点を挙げる。
- 引用位置の正確さ ── 主張が原文のどこから来たかを、LLM が返す文字位置に頼らず本文検索で確定する。LLM の返す位置は頻繁にずれるため、ここを作り込むことで「引用箇所をクリックで原文に飛ぶ」が実用になる
- 接地性の独立監査 ── 合成した回答をそのまま信じず、各文が出典で裏取れるかを別工程で判定する。裏取れない文は「事前知識・推測の可能性」として明示する
- 採点の公平性 ── 出典一覧が付いている / いないという入力体裁の差だけで減点しない設計とした。他社比較は完全に同一の基準で行い、自社に有利な物差しを使わない
- 経験知の扱い ── 営業ノウハウのような文書は、機械的に細切れにすると意味が壊れる。これらは一つの知見ノートとして扱い、検証より文脈の保持を優先する
- 問いの種別の見分け ── 「特定の対象を調べる問い」と「比較・分析的な問い」を区別し、前者では同名異物の取り違えを防ぐ照合を、後者では分析に適した探索を行う
規模・仕様
| 項目 | 内容 |
|---|---|
| 取り込み元 | PDF / 社内文書 / Google Drive / Web 調査結果 |
| 主張の種別 | 事実・方針・予測・仮説・意見・前提・定義・知見 の 8 種 |
| 主張間の関係 | 支持・矛盾・関連・類似・共起 |
| 品質採点の軸 | 接地性・引用正確性・網羅性・深さ・最新性 の 5 軸(各 0–100) |
| 調査方式 | 複数ラウンドの自律検索 + 出典付与 + 接地性監査 |